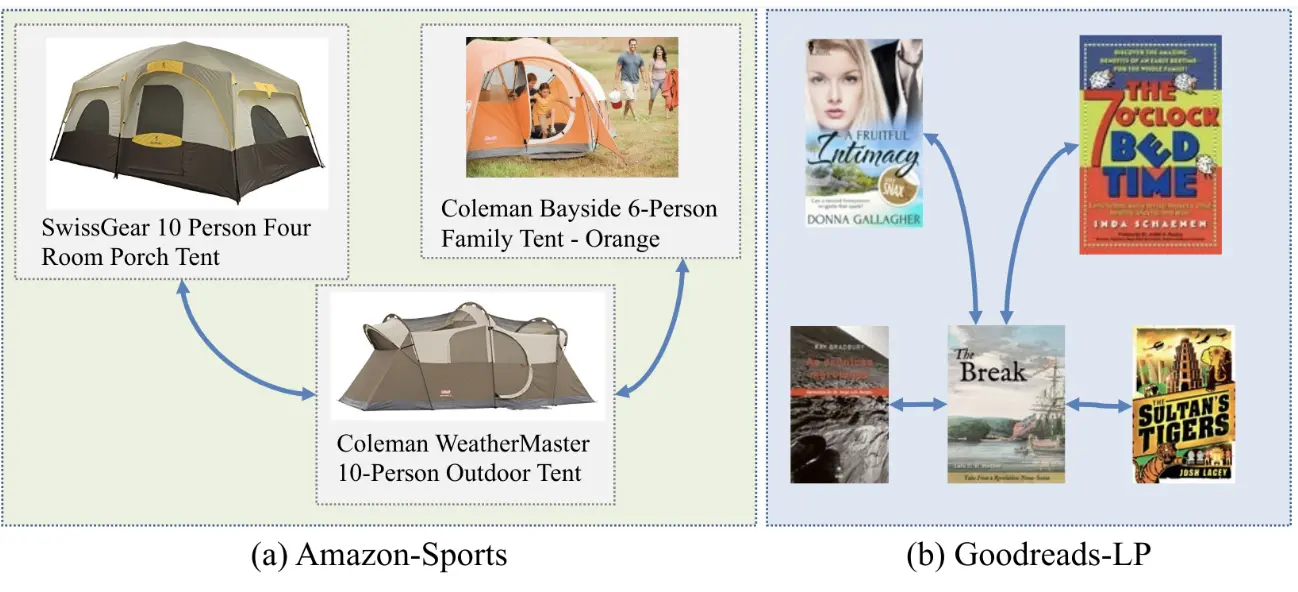
Graph machine learning has made significant strides in recent years, yet the integration of visual information with graph structure and its potential for improving performance in downstream tasks remains an underexplored area. To address this critical gap, we introduce the Multimodal Graph Benchmark (MM-GRAPH), a pioneering benchmark that incorporates both visual and textual information into graph learning tasks. MM-GRAPH extends beyond existing text-attributed graph benchmarks, offering a more comprehensive evaluation framework for multimodal graph learning Our benchmark comprises seven diverse datasets of varying scales (ranging from thousands to millions of edges), designed to assess algorithms across different tasks in real-world scenarios. These datasets feature rich multimodal node attributes, including visual data, which enables a more holistic evaluation of various graph learning frameworks in complex, multimodal environments. To support advancements in this emerging field, we provide an extensive empirical study on various graph learning frameworks when presented with features from multiple modalities, particularly emphasizing the impact of visual information. This study offers valuable insights into the challenges and opportunities of integrating visual data into graph learning.
Back