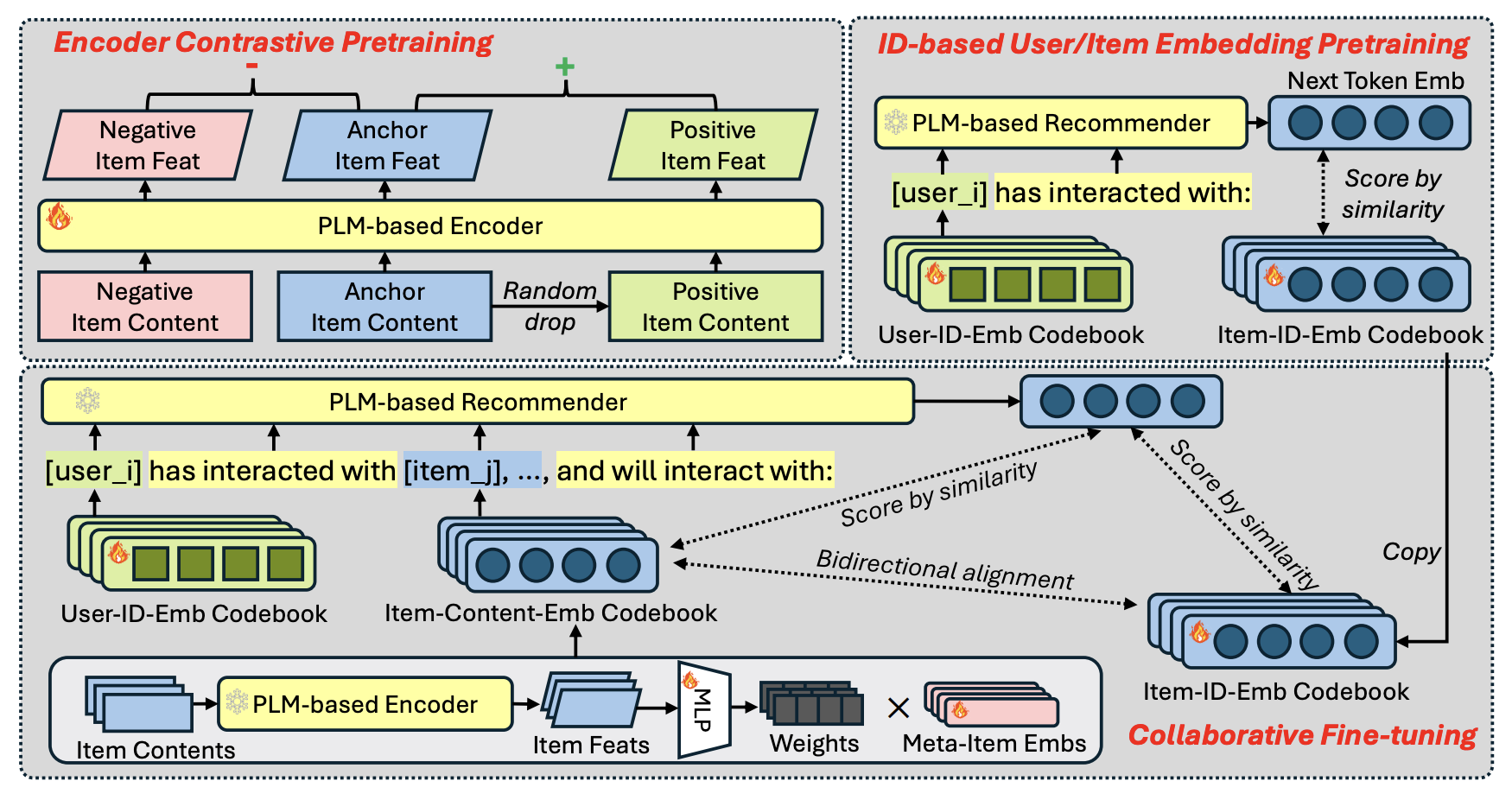
Recently, pretrained large language models (LLMs) have been widely adopted in recommendation systems to leverage their textual understanding and reasoning abilities to model user behaviors and suggest future items. A key challenge in this setting is that items on most platforms are not included in the LLM’s training data. Therefore, existing methods often fine-tune LLMs by introducing auxiliary item tokens to capture item semantics. However, in real-world applications such as e-commerce and short video platforms, the item space evolves rapidly, which gives rise to a cold-start setting, where many newly introduced items receive little or even no user engagement. This poses challenges in both learning accurate item token embeddings and generalizing efficiently to accommodate the continual influx of new items. In this work, we propose a novel meta-item token learning strategy to address both these challenges simultaneously. Specifically, we introduce MI4Rec, an LLM-based approach for recommendation that uses just a few learnable meta-item tokens and an LLM encoder to dynamically aggregate meta-items based on item content. We show that this paradigm allows highly efficient and accurate learning in such challenging settings. Extensive experiments on Yelp and Amazon reviews datasets demonstrate the effectiveness of MI4Rec in both warm-start and cold-start recommendations. Notably, MI4Rec achieves an average performance improvement of 20.4% in Recall and NDCG compared to the best-performing baselines. The implementation of MI4Rec is available at https://github.com/zhengzaiyi/MI4Rec
Back