Rethinking the role of Graph Neural Networks in Knowledge Graph Completion
Knowledge Graphs (KGs) are an efficient method to store relational and typically factual data (e.g. Freebase, NELL, and ConceptNet). They are used for various applications including search, recommendation, and question-answering systems. However, real-world KGs are often incomplete and sparse, due to mismatches between real relationships and observed ones -- these systems struggle to catch-up to the ever-changing body of human knowledge. In response, Knowledge Graph Completion (KGC) aims to predict and fill in these missing relationships. In recent years, several recent works have suggested that a common class of graph neural networks (GNNs), known as Message Passing Neural Networks (MPNNs), are strongly effective for KGC owing to their strengths in modeling graph data. A key feature of MPNNs is the message passing (MP) process, by which nodes exchange information with each other in an iterative process, passing information over the graph. Researchers have invested considerable efforts in developing advanced MP protocols to model KG information and achieve strong KGC performance.
In a paper titled Are Message Passing Neural Networks Really Helpful for Knowledge Graph Completion? presented at this year's ACL 2023, we made a surprising discovery with our collaborators: we found that the considered-crucial MP component in MPNNs is not in fact the cause of reported improvements in performance on several KGC benchmarks. We demonstrate this by replacing the MP module with a Multi-Layer Perceptron (MLP) in several KGC-based MPNN models and test them across diverse datasets. Remarkably, these MLP-based models achieved performance on par with their MPNN counterparts. Through thorough investigation, we found that MP has almost no effect on the performance; instead, other components like the scoring and loss functions had an unexpectedly profound impact. Leveraging these insights, we proposed an ensemble model that utilizes multiple MLPs to outperform MPNN-based models with a fraction of the computational cost, offering a more efficient approach to KGC.
Does Message Passing Really Help KGC?
In our investigation of MPNN-based KGC models we concentrated on three key components (see Figure 1): message passing, scoring functions, and loss functions. Until now, the key contributor to the performance of MPNN-based KGC models has been elusive. Conventional wisdom often credits MP as the primary contributor, prompting our line of questioning: Does message passing really help KGC? To this end, we replaced the MP module with an MLP for multiple popular MPNN models (including CompGCN, RGCN, and KBGAT), holding other architectural details constant for fairness.
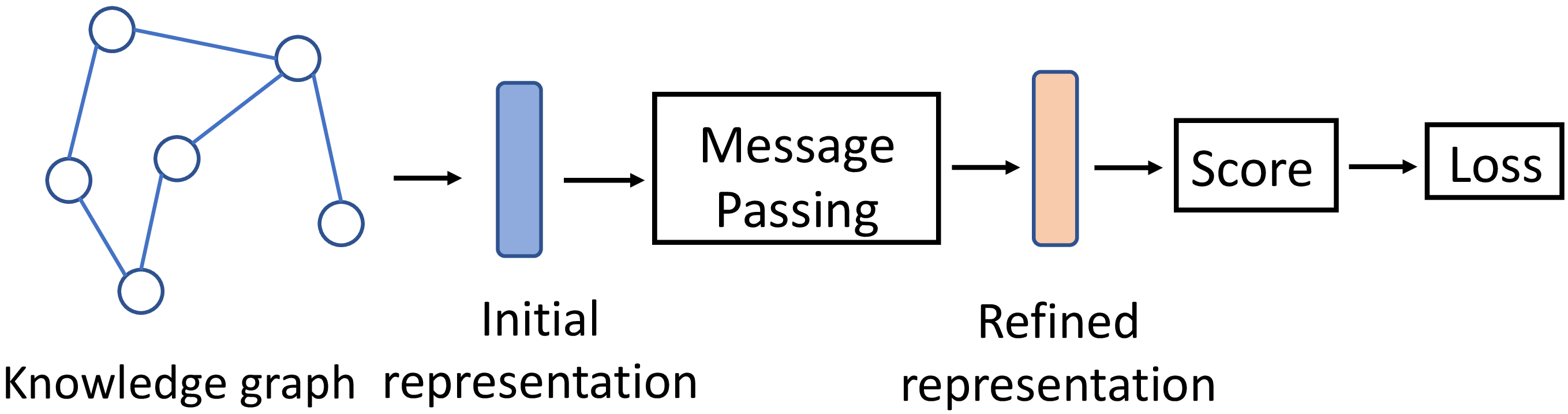
Figure 2 presents our findings on the popular FB15K-237 dataset: notably, MLP-based counterparts achieve comparable performance to each respective MPNN-based model (see our paper for similar findings on other datasets), implying the limited value of MP.
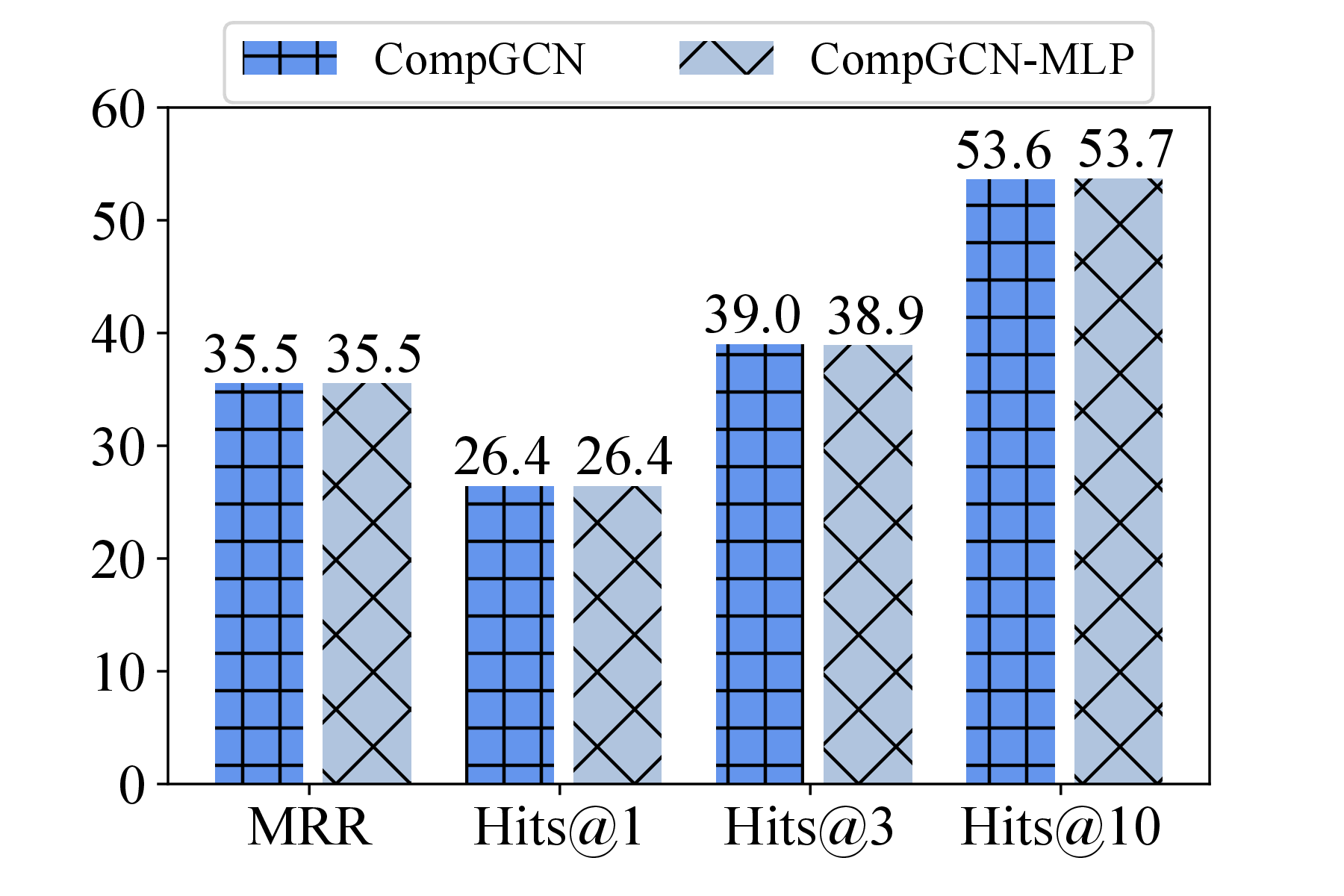
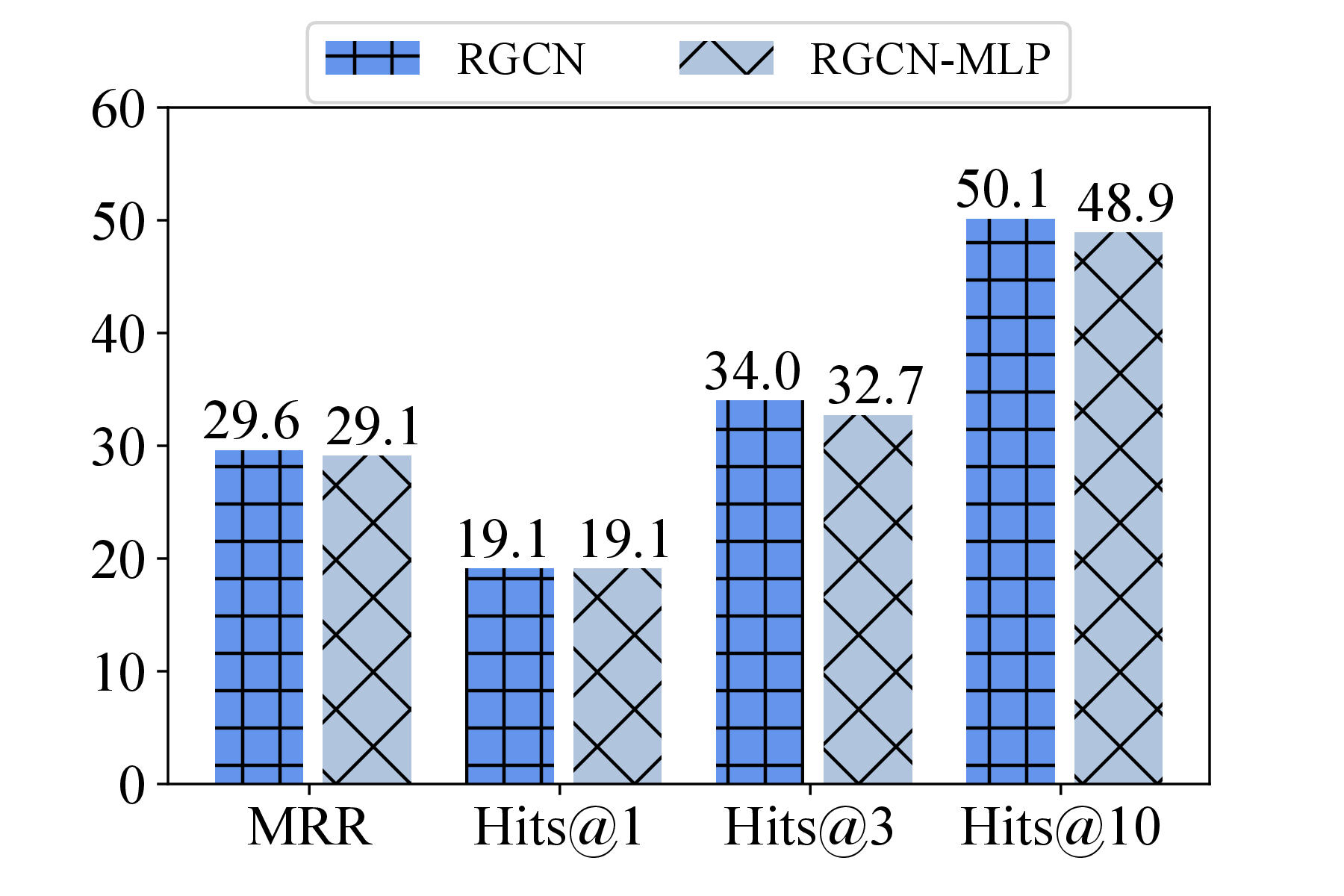
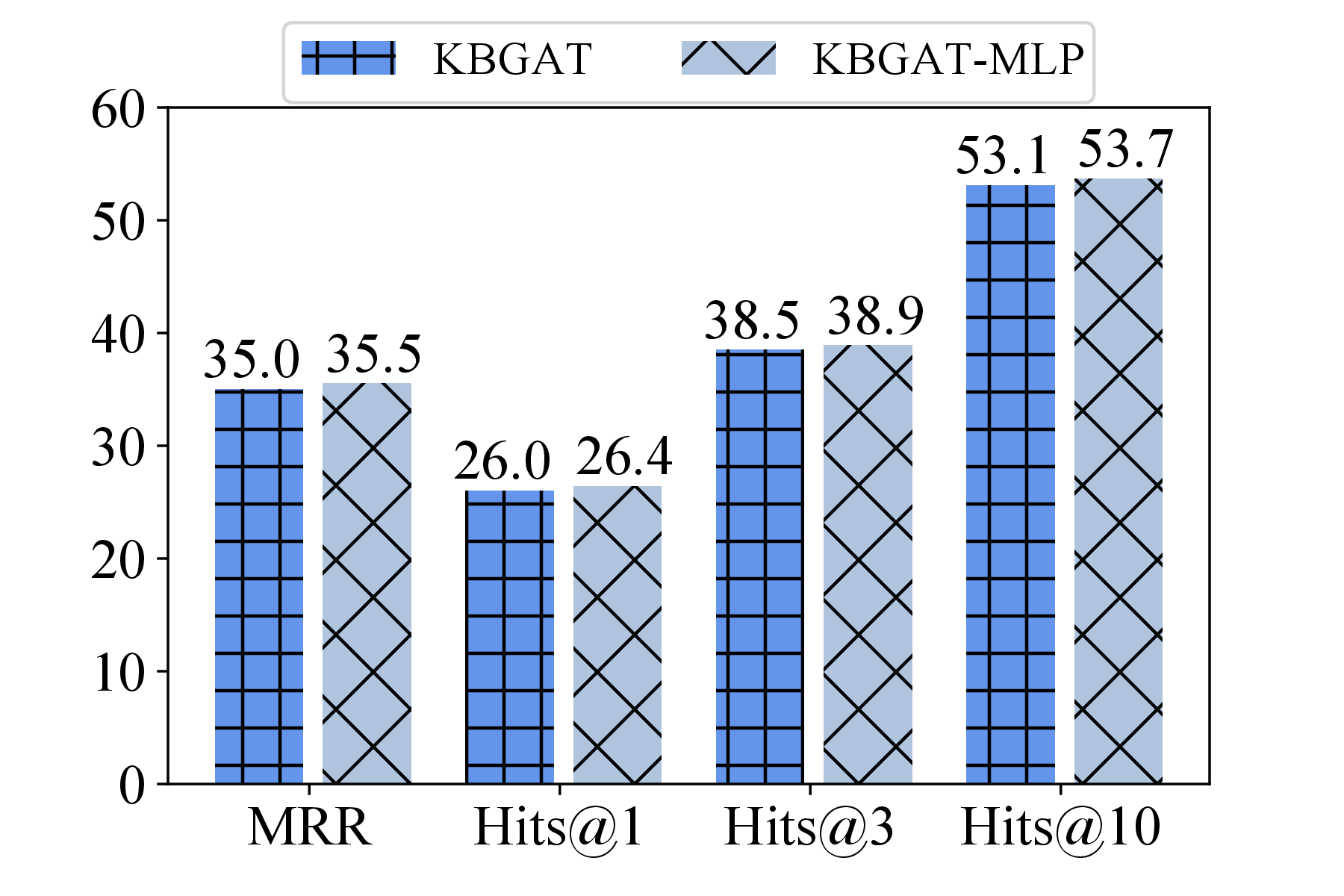
Unveiling the limited influence of MP naturally prompts the question: What components are truly helpful in enhancing performance? This leads us to investigate the remaining components of MPNN-based KGC models: scoring and loss functions.
Scoring and Loss Functions in MPNN-based Models
Scoring Function. In the original setting, CompGCN and KBGAT employ ConvE as their scoring function, while the RGCN uses DistMult. We expand our investigation to observe the performance of CompGCN and KBGAT with DistMult and RGCN with ConvE. All other settings are fixed during this investigation.
Figure 3 presents several intriguing insights: Firstly, it’s evident that CompGCN, RGCN, and KBGAT’s performance fluctuates under different scoring functions. This demonstrates that the choice of scoring function strongly influences the performance in a dataset-dependent manner. Secondly, a performance disparity still exists between CompGCN (or KBGAT) and RGCN on FB15K-237, even when they utilize the same scoring function (either DistMult or ConvE). This suggests that the scoring function is influential but not the sole factor impacting the model performance.

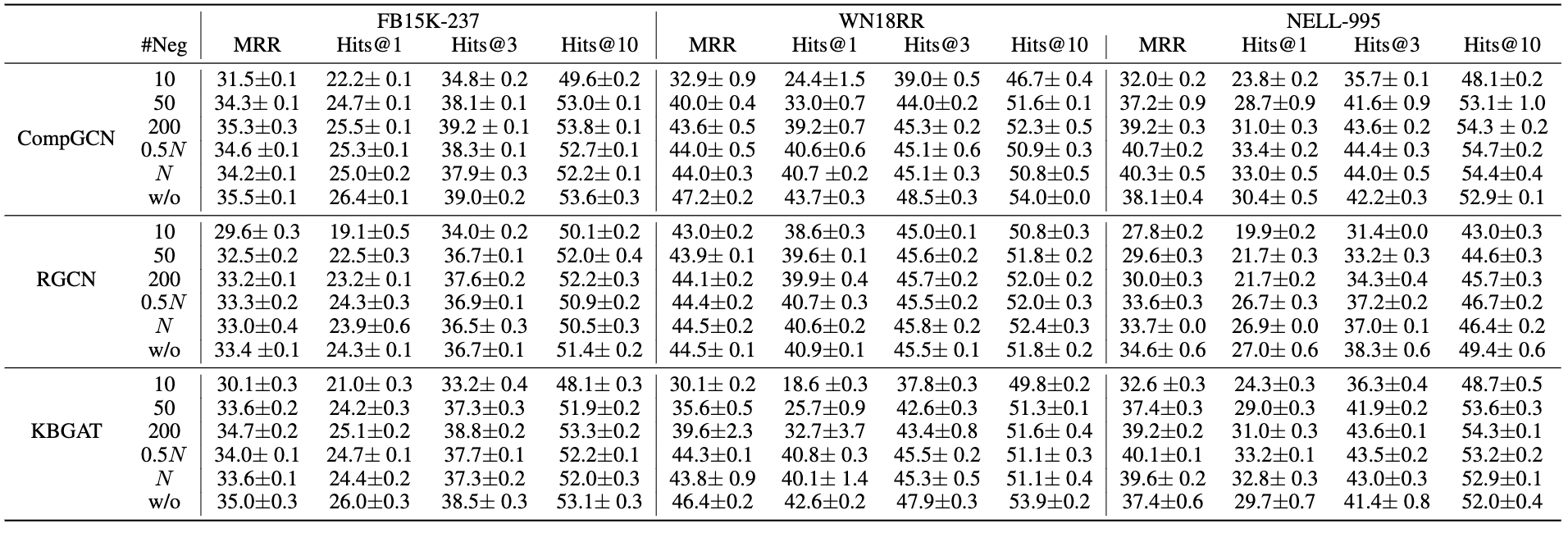
Loss Function. CompGCN, RGCN, and KBGAT all adopt the BCE loss. One major difference however is in the number of negative samples used in training. While CompGCN and KBGAT utilize all negative samples for each positive sample, RGCN only randomly selects 10. As such, we investigate the impact that varying the number of negatives per positive sample has on the performance.
Results are presented in Figure 4, where “w/o” denotes utilizing all negative samples, and N is the number of entities in KG. The results indicate that the quantity of negative samples plays a critical role in model performance, concurring with prior work. Increasing the number of negative samples generally improves performance. However, utilizing all negative samples isn’t a prerequisite for achieving superior results. This is noteworthy as employing all negative samples incurs higher computational costs. Hence, a thoughtful selection of the number of negative samples, tailored to each model and dataset, is important.
MLPs with Various Scoring and Loss Functions
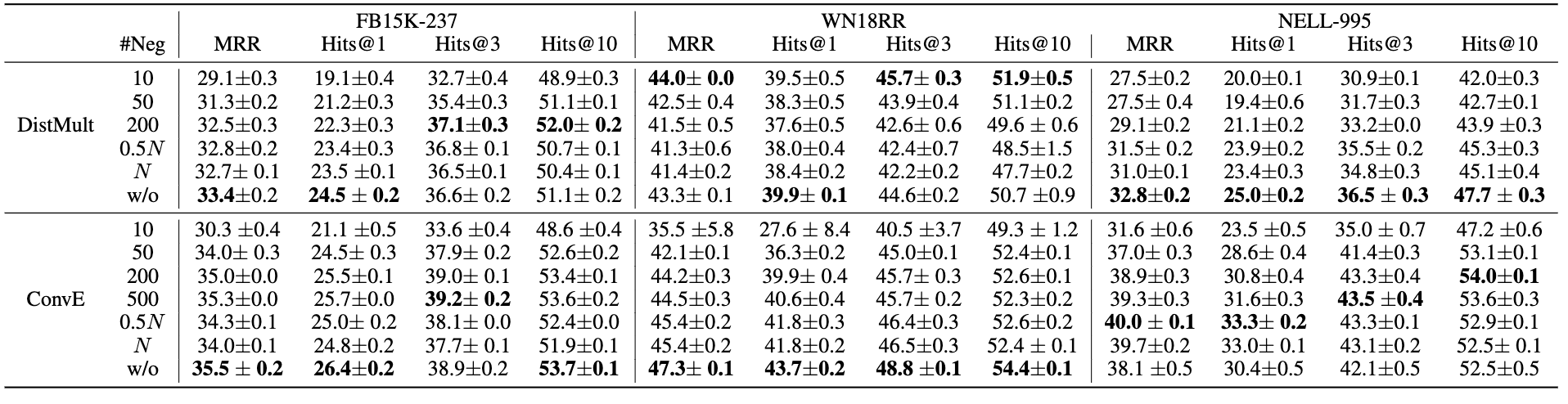
Drawing on our previous analysis, we questioned the necessity of MP in KGC. A negative finding encouraged us to explore the potential of creating efficient MLP-based methods for KGC, which, suggests promise, given that MLP-based methods enjoy superior efficiency during both training and inference phases, owing to the absence of MP operations. Similar to the MPNN models, we first study the impact of the scoring and loss function in MLP models.
Our findings, presented in Figure 5, further underline the non-essential role of MP in KGC. Our MLP-based models can achieve comparable or even stronger performance than MPNN models. We also note the continued significant influence of (dataset dependent) scoring and loss functions on MLP-based KGC model performance. This variability implies that the influence of the scoring and loss functions, especially the negative sampling strategy, differs across datasets.
Ensembling MLPs
To account for this variation, we next explore ensembling these configurations to enhance performance. By doing so, models that utilize different combinations of scoring and loss functions can complement one another. We select a few MLP-based models that demonstrate promising performance on validation sets and integrate them for final prediction. The results are shown in Figure 6, where we use MLP-ensemble to denote the ensemble model. Impressively, this model outperforms both the leading individual MLP-based methods and MPNN-based models. The performance boost is particularly noticeable on FB15K-237 and NELL-995. This finding also underlines the non-essential nature of the MP component for KGC. Furthermore, it hints at the complementary roles of scoring and loss functions.

Conclusion
In a surprising discovery, we found that MLP-based models achieve competitive performance compared with three well-regarded MPNN-based models - CompGCN, RGCN, and KBGAT - across an array of datasets. This outcome challenges the preconceived notion that MP operations common in GNNs are the critical component for high-performance of these models. Our results highlight the previously underappreciated roles played by both the scoring and loss functions in KGC. We observe that the proper combination of these two components varies considerably between datasets. These insights led us to propose an ensemble approach using MLP-based models. This approach not only outperforms MPNN-based ones in task performance, but also simplicity and scalability. Our findings lay groundwork for future explorations in rethinking the role and design of GNN models in KGC applications.