Accelerating Link Prediction Inference with Knowledge Distillation
co-authored with Zhichun Guo, William Shiao, Shichang Zhang, Yozen Liu, Nitesh V. Chawla and Neil Shah
Link prediction is a critical problem with diverse practical applications, including knowledge graph completion, social platform friend recommendations, and item recommendations on service and commerce platforms. Graph Neural Networks (GNNs) have shown outstanding performance in link prediction tasks. However, the practical deployment of GNNs is limited due to the high latency caused by non-trivial neighborhood data dependencies. On the other hand, Multilayer Perceptrons (MLPs) are known for their efficiency and widely adapted in industry, but the lack of relational knowledge makes them less effective than GNNs.
In our work titled “Linkless Link Prediction via Relational Distillation,” accepted at ICML 2023, we propose a novel approach that leverages cross-model distillation techniques from GNNs to MLPs. This enables us to take advantage of the performance benefits of GNNs and the speed benefits of MLPs for link prediction tasks. We began by exploring two direct distillation methods, namely logit-based and representation-based matching. However, we observed that these methods were ineffective for link prediction tasks, which we hypothesized was due to their inability to capture relational knowledge which is critical to the link prediction task. To address this limitation, we introduce a relational distillation framework called Linkless Link Prediction (LLP), which focuses on matching the relationships between each node and other nodes in the graph.
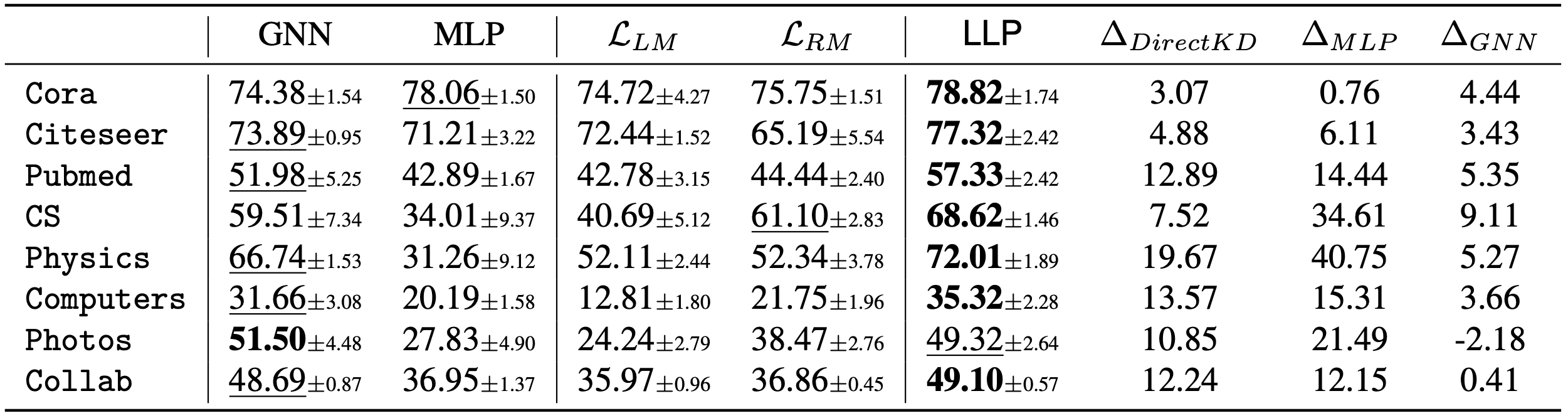
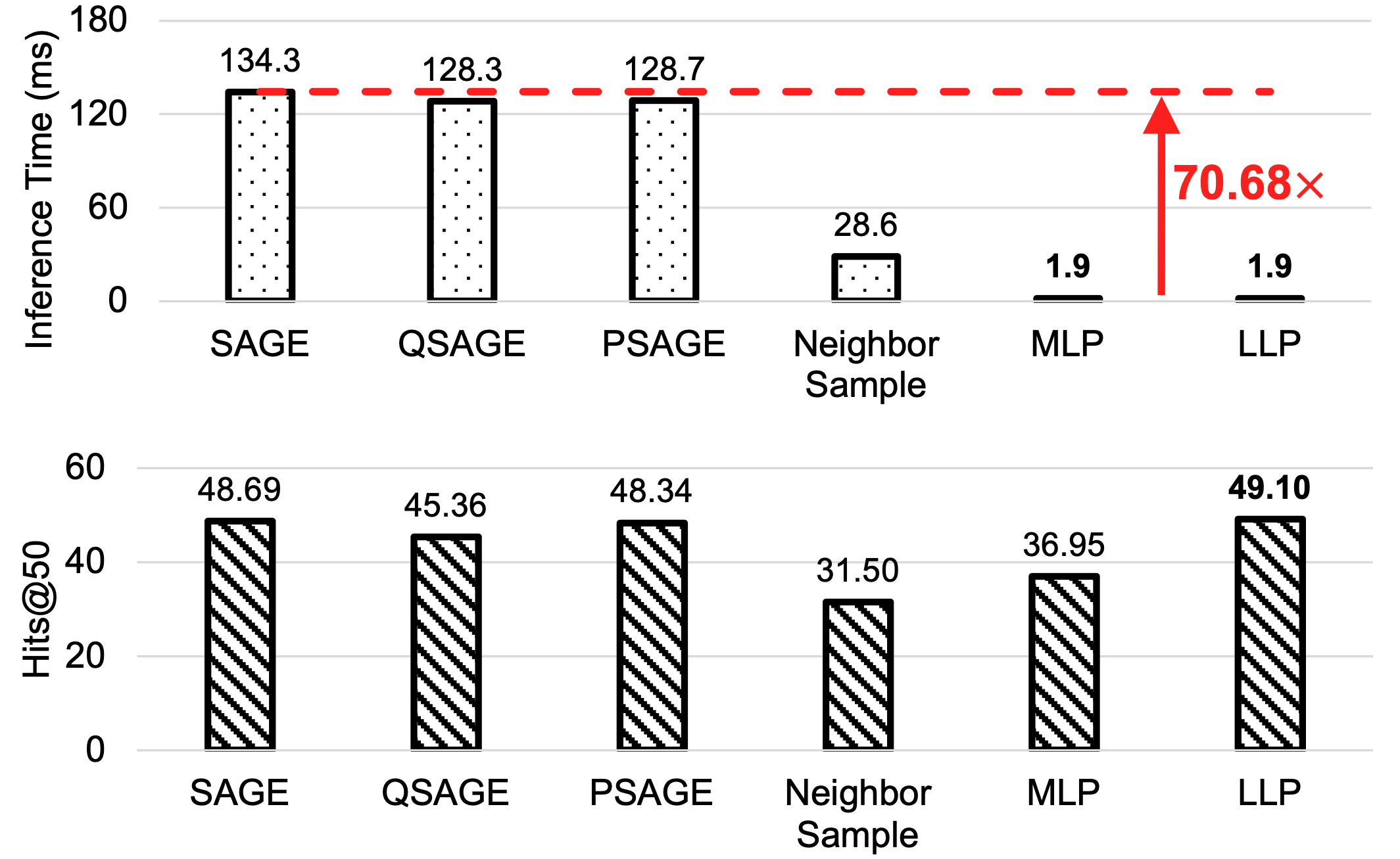
Through extensive experiments, we demonstrate that LLP consistently outperforms MLPs and the two direct distillation methods in both transductive and production settings. Moreover, LLP achieves comparable or superior performance to teacher GNNs on 7 out of 8 datasets in the transductive setting. Particularly noteworthy is the performance of LLP on cold-start nodes, where it surpasses teacher GNNs and standalone MLPs by an average of 25.29 and 9.42 on Hits@20, respectively. Additionally, LLP exhibits significantly faster inference times compared to GNNs, such as being approximately 70.68x faster on the large-scale Collab dataset.
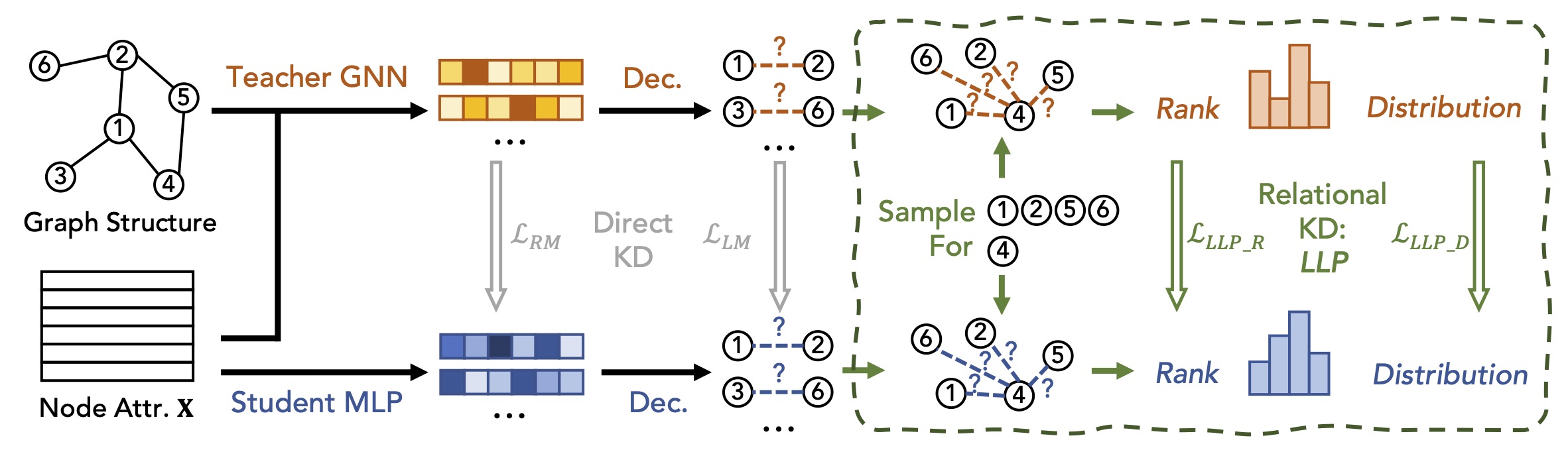
Direct Distillation methods
In this work, as illustrated in Figure 1, we adopt the commonly used encoder-decoder framework for the link prediction task. The encoder learns node representations using GNNs or MLPs, and the MLP decoder predicts link existence probabilities. Initially, we applied two direct knowledge distillation methods: logit-matching and representation-matching (the gray arrows in Figure 1). In the logit-matching method, we generate the soft score for each candidate node pair with the teacher GNN model, and train the student to match the teacher’s prediction on each candidate. For the representation-matching, we align the student’s learned latent node embedding space with the teacher’s. However, empirical observations revealed that neither method was capable of distilling sufficient knowledge for the student model to perform well in link prediction tasks. We hypothesize that link prediction, unlike node classification, heavily relies on relational graph topological information, which is not effectively captured by direct distillation methods.
Relational Distillation Methods (LLP)
In accordance with our intuition regarding preservation of relational knowledge, we propose LLP, a relational distillation framework. Instead of focusing on matching individual node pair scores or node representations, LLP focuses on distilling knowledge about the relationships of each node (e.g., node 4 in Figure 1) to other nodes (referred as context nodes, e.g., nodes 1, 2, 5, 6 in Figure 1) in the graph. We propose two relational matching objectives to achieve this goal: rank-based matching and distribution-based matching. The key components of LLP are introduced as follows:
- Context Nodes Sampling: For each anchor node, LLP samples some nearby nodes by repeating fixed-length random walks several times and randomly samples another few nodes from the whole graph to serve as the context nodes.
- Rank-based Matching: LLP utilizes the ranking of the context nodes w.r.t. the anchor node induced by the teacher to teach the student.
- Distribution-based Matching: LLP uses the KL divergence between the teacher predictions and student predictions, centered on each anchor node to train the student.
Effectiveness of LLP
We evaluated LLP under various settings, including transductive, production (new nodes and edges appear during testing), and cold-start (testing nodes appear without edges) scenarios. The experimental results demonstrate that LLP consistently outperforms MLPs and the two direct distillation methods. Notably, as Table 2 shown, LLP achieves superior performance compared to the teacher GNN model on 7 out of 8 datasets in the transductive setting.
Efficiency of LLP
Figure 3 shows that LLP not only improves performance but also offers significant speed improvements compared to GNNs and other inference acceleration methods. The experimental results show the efficiency gains achieved by LLP, reinforcing its practical applicability for large- scale link prediction tasks.
Conclusion
In this work, we address challenges related to deploying GNNs for link prediction at scale. By exploring cross-model distillation techniques from GNNs to MLPs, we introduce LLP as a novel framework that combines the strengths of both models. Our experiments demonstrated the effectiveness and efficiency of LLP in various settings. With LLP, we achieve improved performances as well as faster inference times, making it a promising solution for large-scale link prediction tasks that require both accuracy and efficiency. Our work provides valuable insights into developing effective knowledge distillation frameworks for GNNs and also serves as a new perspective for effective, efficient, and scalable link prediction.